How to Use the NIST
Scientific Indexing Resource for CORD-19 Search Engine
What
is the NIST Scientific Indexing Resource for CORD-19?
The NIST CORD-19 indexing resource is a database built on semantic terms and phrases that are automatically generated to describe the text data in the CORD-19 dataset. The website for accessing the database, takes advantage of auto-filling during the text search to direct the user to terms and phrases that have been extracted from the dataset. The searches yield sentence fragments from the dataset to provide context around the search terms and facilitate the selection of relevant results. Scientific literature or related information corresponding to the selection can then be identified in Google Scholar or with a general Google search. The automated semantic terms and phrases for the data selection can also viewed to initiate other searches that identify different scientific literature that may have deep connections to main topic of interest.
How does the Database
work?
The database uses a novel root and rule-based natural language processing approach to information indexing and searching, https://www.nist.gov/programs-projects/novel-root-and-rule-based-natural-language-processing-nlp-approach-information
that has been developed in the MML’s Biosystems and Biomaterials Division in
collaboration with ITL’s
Software and
Systems Division
. The algorithm extracts
semantic keywords and phrases from the text files in the CORD-19 dataset
enabling the generation of a database for semantic searches.
How to Use the NIST CORD-19
Scientific Indexing Resource
I. Access the database
A.
Go to randr19.nist.gov
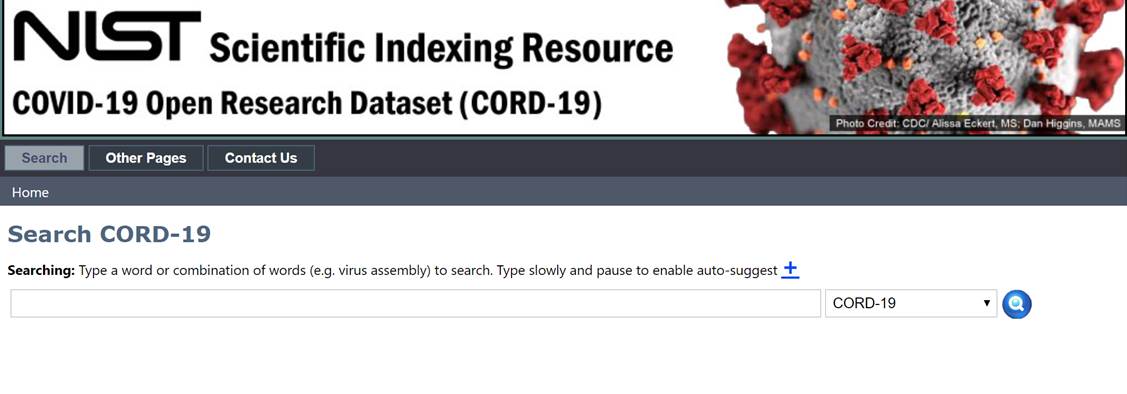
II. Performing a search
A. Enter a search term in the box (e.g. lysosome). Type slowly to generate a dropdown list of autofill phrases (i.e. topics) present in the database.
B.
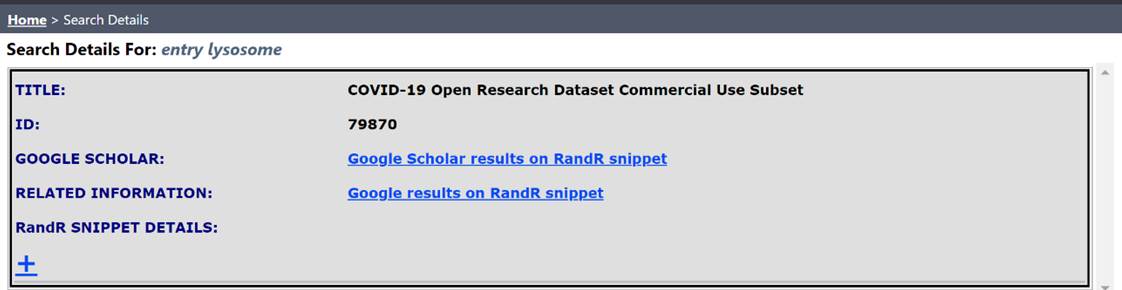
Select “entry lysosome,” which yields 12 sentence fragments (i.e. snippet). Below
is a portion of the resulting page.
C. Each ID corresponds to a fragment of text in the CORD-19 dataset. The snippet provides context around the search phrase to facilitate identification and selection of most relevant topics.
D. Select an item in the list to generate an interface page to possibly identify original source material or related information with the Google search engines.
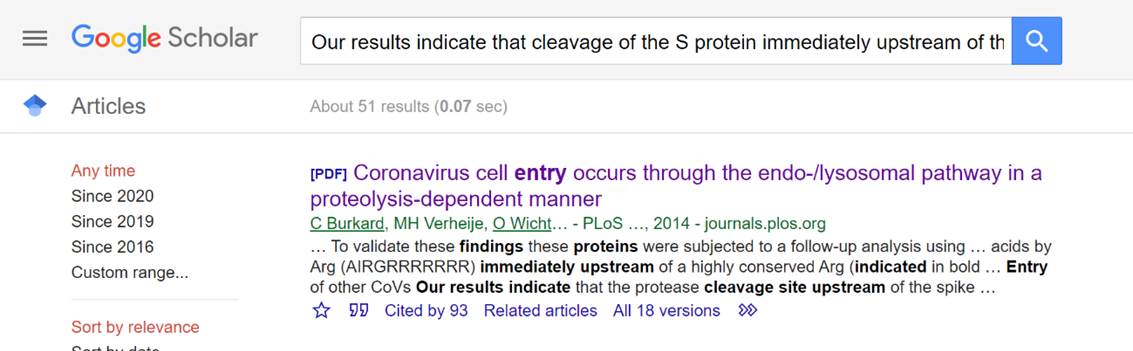
E. Select the Google Scholar link to possibly identify the original source material for the text fragment in the CORD-19 dataset.
F.
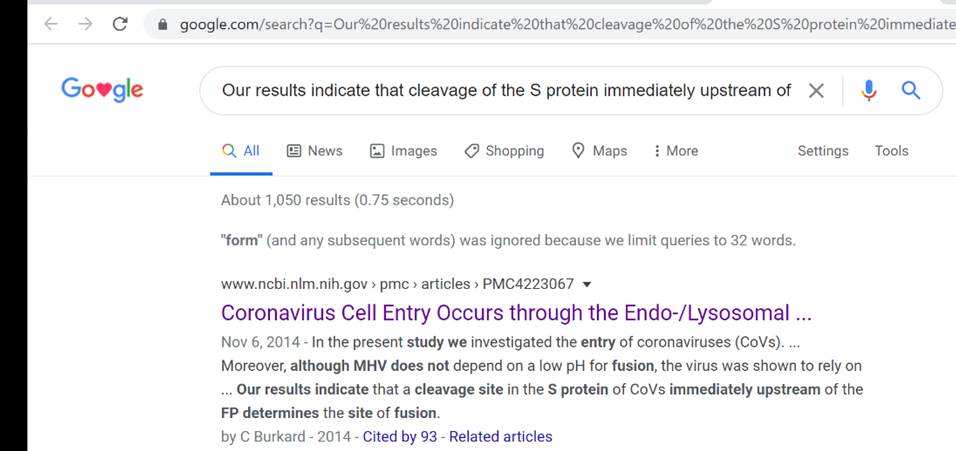
Select Google to identify related information that maybe indexed in the general
search engine.
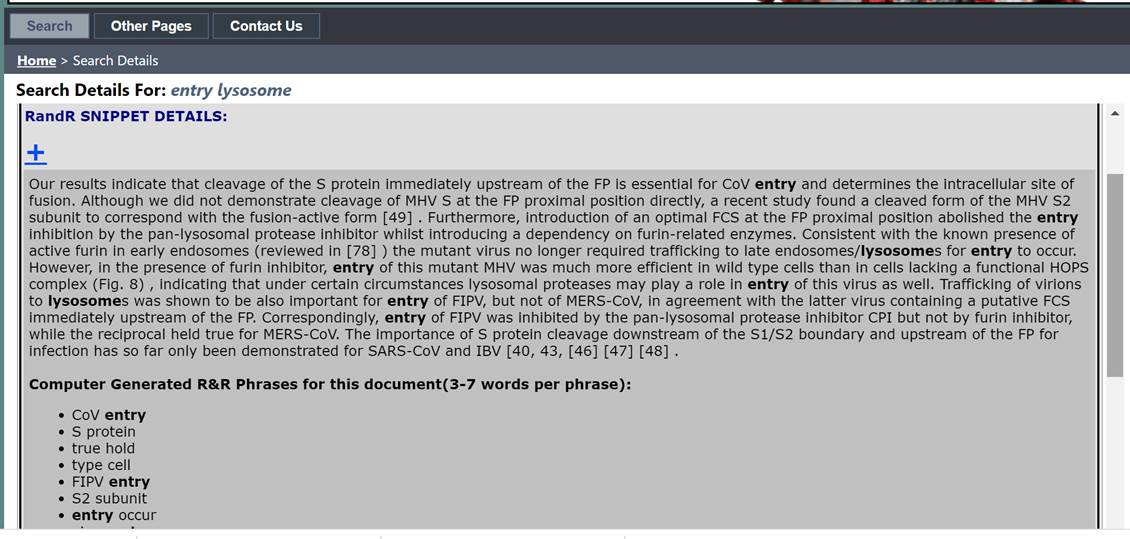
G. Select the “±” button on “RandR SNIPPET DETAILS:” to show the complete text fragment that corresponds to the search term and the additional semantic phrases that have been extracted from the text fragment. These phrases could be used to initiate new searches to find literature and other information related to the main search topic through possibly unexpected connections.